Highlights
- Prompt engineering guides what an AI should do, while context engineering ensures the model has the right information, tools, and history to reliably execute complex tasks.
- Most AI failures stem from missing, outdated, or poorly structured context, not the model itself; clever prompts alone aren’t enough.
- Effective context engineering involves dynamic information flow, tool integration, memory architecture, and context optimization to provide relevant, timely, and structured data.
- Context engineering adds complexity and cost, so it’s most valuable for multi-turn, high-stakes, or production-grade systems, while simpler tasks may not require it.
Remember the early days of ChatGPT and prompt engineering? Mastering prompt phrasing felt like a magic trick. But today, with AI becoming deeply integrated into workflows—from enterprise chatbots to autonomous agents—that magic trick isn’t enough.
Prompt engineering taught us how to ask a question. Context engineering teaches AI systems how to actually deliver on complex tasks. Industry leaders are calling it a fundamental shift in how we build AI applications.
Why not cleverness, but context drives performance?
Think of a language model like a brilliant consultant who just parachuted into your company. They've read every business book ever written, but they don't know your specific situation, your data, your tools, or your constraints.
LLMs have extensive training knowledge but lack real-time awareness of:
- Your current user’s history and preferences
- Your product data and business logic
- Live tool outputs and API responses
- Your application’s specific requirements
LLMs don’t come with contextual awareness. They can’t remember what your user just said five minutes ago. They don’t know what “next Friday” means unless you tell them what today is. They’re brilliant—but only within the boundaries of what you feed them.
That’s why clever prompts can only take you so far. If your AI feels disconnected, brittle, or forgetful—it’s not the model’s fault. It’s because you haven’t engineered the context it needs to succeed.
This is the central insight behind context engineering: AI doesn’t need more cleverness—it needs more clarity.
Why AI agents fail? And it’s not what you think!
Here’s what teams are discovering the hard way:
Most AI failures aren’t model failures. They’re context failures.
Common symptoms:
- Your customer support agent forgets the previous question.
- Your data analyst overlooks key information in documents.
- Your task planner suggests actions without checking feasibility.
A recurring theme in production deployments:
“We spent months perfecting the prompts. Still, our agent kept failing on edge cases.”
These issues rarely stem from prompt design. They happen because the model doesn’t have what it needs to think clearly – a document that wasn’t retrieved, a past interaction that was forgotten, or a tool output the model couldn’t parse.
The model didn't fail. The context system did.
What is context engineering?
Context engineering is the practice of designing systems that provide the right information to a model—in the right format, at the right moment, for the specific task at hand.
It’s not about tweaking prompts. It's about building information architectures that consider:
- What information the model needs
- When it needs that information
- How to present it effectively
- What to exclude to avoid confusion
- How to manage costs and performance
Instead of crafting a perfect prompt, you're building an information pipeline that adapts to each situation.
Prompt engineering vs context engineering: A critical distinction
As AI applications mature, the difference between prompting and context engineering becomes crucial:
Prompt engineering focuses on crafting effective instructions—the "what to do" part. It's essential for clear communication but represents just one component of the system.
Context engineering encompasses the entire information ecosystem—the "what to know" part. It ensures the model has access to relevant data, tools, and history throughout its operation.
Here's how they differ in practice:
Prompt engineering vs. Context engineering
| Aspect |
Prompt engineering |
Context engineering |
| Focus |
Writing clear instructions |
Building dynamic information systems |
| Scope |
Single interaction |
Multi-turn conversations and workflows |
| Complexity |
Template design |
System architecture |
| Failure Mode |
Unclear instructions |
Missing or conflicting information |
| Scalability |
Limited by prompt size |
Designed for production systems |
In short: a strong prompt sets the direction, but rich context fuels the journey.
One without the other limits your results—prompting guides the model’s behavior, while context ensures it has the knowledge to respond with relevance, accuracy, and depth.
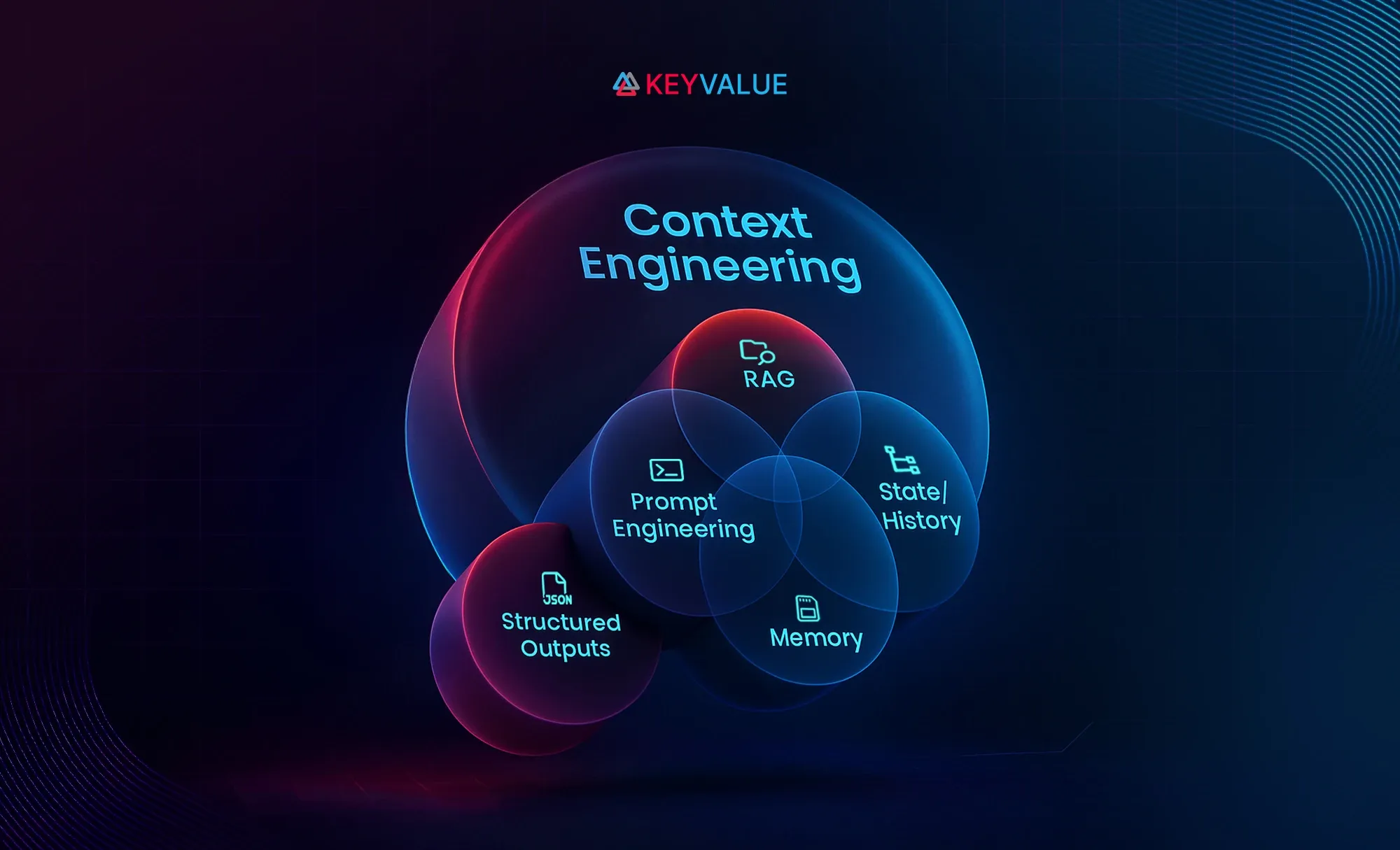
The four pillars of context engineering
Let’s break down what it takes to engineer effective context for an LLM:
- Dynamic information flow
Aggregate context from diverse sources—vector stores, relational databases, APIs, documents, and conversation history—using retrieval methods that balance relevance, freshness, and efficiency.
- Tool integration & orchestration
Provide the AI with clear, structured tool definitions, manage error recovery and retries, and maintain execution state so multi-step workflows run reliably in production.
- Memory architecture
Combine short-term (current task), episodic (recent sessions), and long-term (persistent knowledge) memory while controlling token budgets to ensure continuity without bloating the context window.
- Context optimization
Deliver inputs in structured, concise formats (e.g., JSON, tables), apply compression that preserves meaning, and prioritize information so the model sees the most critical details first.
When to skip context engineering: Costs, complexity, and alternatives
Context engineering adds complexity and cost—sometimes without real benefit. Skip it when:
- Tasks are simple & stateless
- Single-turn Q&A, translations, summarizations, or clear-cut classification
- Template-driven outputs that don’t need history or retrieval
- Budgets are tight
- Each extra token costs money
- Long conversations quickly become expensive
- ROI doesn’t justify the overhead
- Speed is critical
- Real-time systems (<100ms) for trading, gaming, or emergency use cases
- Absolute reliability is required
- High-stakes domains like medical, financial, safety-critical, or legal systems
- Infrastructure isn’t ready
- No vector database, retrieval pipeline, monitoring, or engineering capacity
Better alternatives: Use traditional APIs, rule-based flows, templating, fine-tuned models, or human-in-the-loop review for simpler, deterministic needs.
Remember: The best AI system is often the simplest one that works.
The hidden challenges nobody talks about
Even with the right design, context engineering comes with real-world limitations:
- The context window trap – Large token windows degrade in quality before reaching their limits, suffer from “lost in the middle” issues, and can be costly—long chats can run $50–$100 in tokens.
- Failure cascades – In multi-step workflows, small errors multiply fast. At 95% reliability per step, success drops to 36% over 20 steps. Production-grade systems often need 99.9%+ per step.
- Context conflicts – Outdated data, conflicting tool outputs, and contradictions between past memory and current state can mislead the model. Even error messages can leak into future reasoning.
Context engineering in practice
Frameworks like LangGraph, LlamaIndex, Semantic Kernel, and AutoGen are now enabling developers to:
- Construct context-aware agent graphs
- Integrate memory, tools, and retrieval
- Dynamically update working memory (e.g., scratchpads or plan documents)
- Avoid token overflow by smart chunking and compression
And big players like Anthropic and OpenAI are doubling down on context-related capabilities: longer windows, model-based memory, and structured reasoning protocols.
The path forward
Context engineering is still evolving rapidly. What works today might be obsolete in six months.
However, certain principles are emerging:
- Design for failure - Assume every component can fail
- Measure everything - You can't optimize what you don't track
- Start simple - Complex context systems often perform worse
- Test with real data - Synthetic tests miss edge cases
- Plan for costs - Token usage can explode unexpectedly
Mastering AI requires context, not just prompts
We're in the early stages of a fundamental shift. Prompt engineering was our first attempt at programming with natural language. Context engineering is how we build reliable, scalable AI systems.
The winners won't be those with the cleverest prompts. They'll be the ones who master the art and science of providing AI with exactly what it needs, exactly when it needs it. Because in the end, the difference between a demo and a production system isn't the model—it's the context.
Important note: Context engineering is an emerging practice with no proven best practices yet. We're all still figuring this out. This blog reflects current thinking from teams building production systems, but the field is evolving rapidly. Read our blog here to find how we leveraged Context engineering in our product development journey.
As an AI-first product development partner, KeyValue helps startups, scale-ups, and enterprises build intelligent, scalable, context-aware AI agents that redefine the future.
FAQs
- Why do AI systems fail, and how does context engineering help?
Most AI failures are not due to the model itself but to missing, outdated, or poorly structured context. Context engineering ensures the AI has the right information, tools, and memory at the right time, preventing errors, forgetfulness, and unreliable outputs in complex tasks.
- What is the difference between prompt and context engineering?
Prompt engineering tells the AI what to do. Context engineering provides the AI with what it needs to know, including the right data, tools, and memory, so it can perform tasks accurately and reliably.
- What is a context engineer?
A context engineer designs and manages the AI’s information ecosystem, ensuring models have access to the right data, tools, and memory at the right time to execute complex, multi-step tasks reliably.
- What are the skills of context engineering?
Key skills include designing dynamic information flows from multiple sources, integrating and orchestrating tools, managing memory (short-term, episodic, long-term), optimizing context structure and relevance, and handling failures while balancing cost and performance.
- What are the four pillars of context engineering?
The four pillars are dynamic information flow for timely data, tool integration and orchestration for reliable execution, memory architecture to manage short- and long-term context, and context optimization to structure and prioritize information effectively.