LLM pretraining relies on massive unlabeled text, making it fundamentally different from traditional ML models trained on smaller labeled datasets.
Data preparation is essential to remove encoding issues, meaningless characters, gibberish text, and duplicate content, all of which can negatively affect model quality and training efficiency.
The data cleaning pipeline includes Unicode normalization, ASCII filtering, repeated sequence removal, gibberish removal, and data deduplication.
Once cleaned, tokenized, and sequence-packed, the data is split into training and validation sets and stored in formats that support fast reading during LLM pretraining.
How do the datasets used for LLM pretraining differ from those used in traditional machine learning (ML) or deep learning (DL) models?
Large Language Models (LLMs) like GPT-4 or Google’s Gemini or Meta LLama represent a major leap in how machines understand and generate human language. Unlike traditional machine learning or deep learning models, which are trained on labeled datasets for task-specific applications (like text classification or named entity recognition), LLMs are trained on vast amounts of unstructured text data from the internet, books, and other sources using an approach called self-supervised learning, where the model learns to predict the next word in a sentence. LLMs are based on transformer architecture and are able to scale to billions of parameters, enabling them to generalize across a wide range of language tasks without being explicitly trained for each one. Models with a significantly larger number of parameters than traditional machine learning models require proportionally large datasets to generalize well; otherwise, they are likely to overfit. This scale of data comes with its own challenges, such as managing, cleaning, and processing it into a format that is compatible for model pretraining.
Large datasets comes with its own caveats
Yes, you heard it right. Large datasets that are scraped from the Web and other sources bear noise with it. This noise includes:
Multiple representations of the same character.
Occurrence of non-English characters (if the model is English-specific, this could be an issue)
Repeated sequence of characters that doesn't add any value to the model
Gibberish/Non-sensical texts often occurred due to encoding or OCR issues
Duplicates
These issues directly affect the quality and reliability of data used for LLM pretraining.
How to handle this
What we need to do is data cleaning. ML models are like garbage in - garbage out. It’s very important to have good quality and enough quantity of data for LLM pretraining, to get a well-performing model.
Unicode normalization:
Normalization makes text comparison reliable by converting all strings to a consistent form. Normalization Form Compatibility Decomposed “NFKD” normalizes the strings and makes it easier for NLP models. Use the `ftfy` package for fixing text encoding issues
Example:
Café -> cafe
Occurrence of non-English characters: Perform ASCII filtering to remove non-English text
Repeated sequence of characters: If we take repeated 8-10 grams of the dataset, we can see that they are repeated characters which provides no information
eg: “- - - - - -- - - -”,
“. . . . . . . . . .”,
“* * * * * * * * * *”
These can be removed using regex patterns
Gibberish text: Due to encoding or OCR issues, some of the data might be corrupted into a nonsensical form
Removing this kind of text is a difficult task since it can come in a variety of forms and representations. Traditional techniques, such as heuristics or Markov chain might result in lower accuracy since they work on the word level.
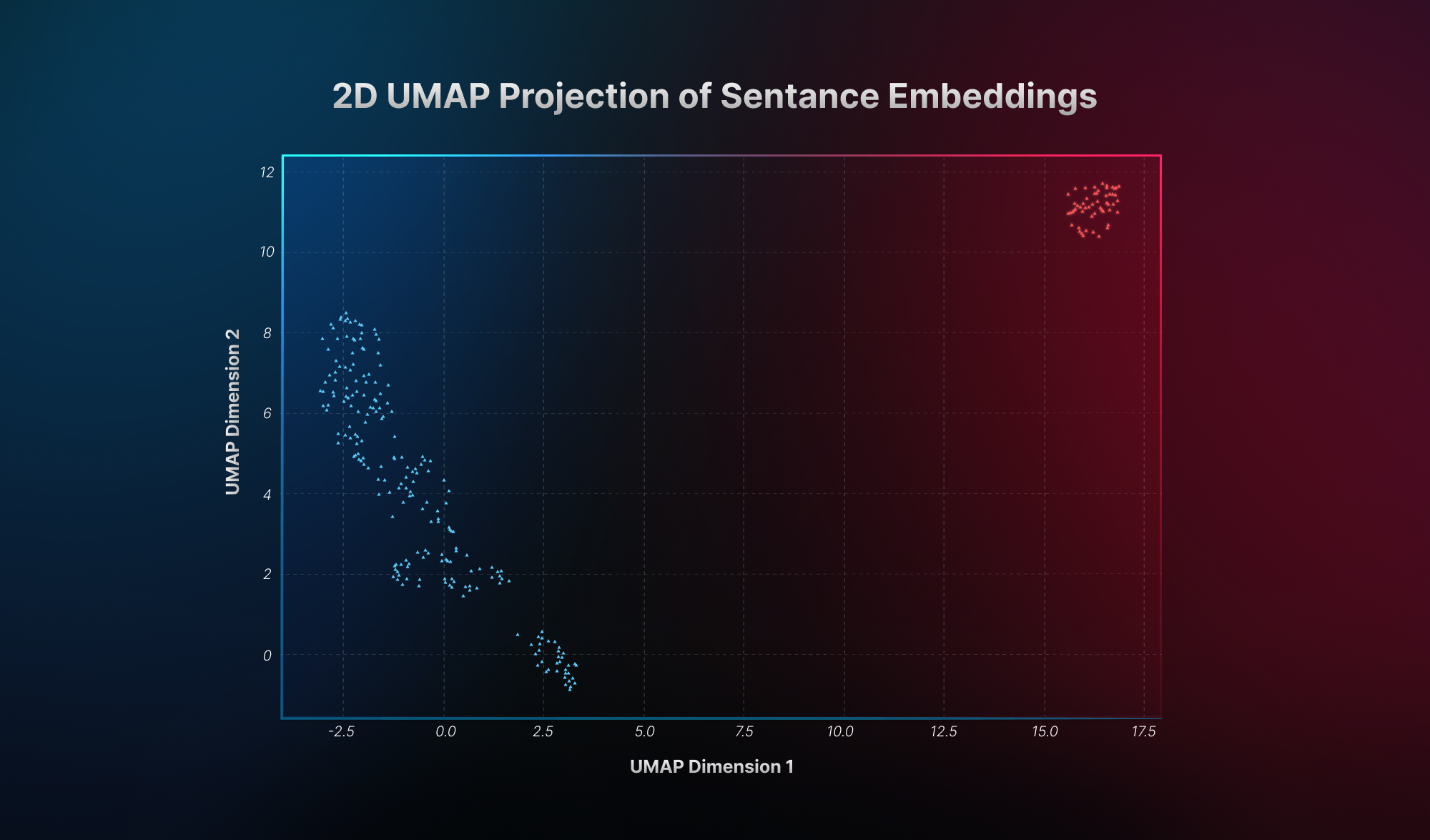
The gibberish text does not possess any semantic information compared to normal text. Using a sentence transformer to capture the embeddings and project that into 2d space helps us understand the semantic difference between gibberish and normal text.
As you can see in the image, gibberish in red color stays far from the normal text, which is represented in blue color. The difference in semantic information helps to flag gibberish data in text corpus
Duplicates: If we carefully observe large-scale web data, we could find that there are many instances of exact and near duplicates. If we don't remove this from the training dataset, this could result in wastage of compute. The model doesn't learn anything new.
A solution to this is `Nvidia Nemo curator Fuzzy deduplication` . NVIDIA NeMo Framework is a scalable and cloud-native generative AI framework built for researchers and PyTorch developers working on LLMs and other state-of-the-art networks. Nemo curator provides GPU accelerated data deduplication, which is crucial for faster run times.
How it works
Computing MinHash Signatures on documents with character-based n-gram
PerformLSH(local sensitive hashing) to find candidate duplicates.
Convert the LSH buckets to edges for the connected components computation.
Due to the approximate nature of Locality-Sensitive Hashing (LSH), near-duplicate documents may be placed into different buckets, with limited overlap between buckets. A GPU-accelerated connected components algorithm is employed to identify all connected components in the graph formed by edges linking documents within the same bucket.
The identified duplicates are removed from the dataset
Once the data is cleaned, the next step is tokenization, a core process in data preparation for LLM pretraining.
Tokenization is the process of breaking up text into smaller pieces, called tokens.
These tokens can be:
Words
Sentences
Subwords (parts of words) or even characters
Why tokenization?
AI models like ChatGPT can’t "see" words. They only work with numbers. Each token gets mapped to a unique number (called an "embedding"), so the model can process it mathematically.
Instead of teaching a computer every possible sentence in English, we teach it to understand smaller pieces — tokens — and how they fit together.
Latest LLMs usually use a special form of subword tokenization (like Byte-Pair Encoding or WordPiece). These allow the model to handle Rare words and new names
When an LLM processes text, it doesn't read an entire book at once. It only sees a limited amount of tokens at a time. This limited portion is called the Context window (or sequence length)
Think of it like how your eyes can only see a few words at a time when reading — not the whole page.
Since we have multiple documents with a lot of text, how can we efficiently create training samples of a given sequence length(number of tokens in a sample)? One approach is to concatenate all into a large text (set of tokens), then split it based on sequence length. This is straightforward, but it introduces a high number of truncations. Recently, a research paper was published on “Fewer truncations improve language modeling”. The paper proposes a data packing strategy - a scalable and efficient method that packs documents into training sequences through length-aware combinatorial optimization. This method completely eliminates unnecessary truncations while retaining the same training efficiency as concatenation. The idea is to eliminate unnecessary document truncations without sacrificing training efficiency. From our experiments, we have observed a 40% reduction in truncations.
Once the data is packed into a fixed sequence length (after padding for shorter sequences), this is split into a train and validation set with an 80/20 or 90/10 proportion. For faster throughput, data is often stored in Arrow format.
Finally, the dataset is ready for LLM pretraining.
Happy pretraining!!!
At KeyValue, we build systems that stay solid; deeply engineered, thoughtfully designed, and ready for the long run. Let's talk.
FAQs
1.Why is data preparation important for LLM pretraining?
Data preparation is important because large web-scraped datasets may contain encoding errors, repeated characters, gibberish text, and duplicates that can mislead the model and waste compute. Cleaning, deduping, and properly organizing the data ensures the LLM trains on high-quality text, improving LLM’s efficiency and performance.
2.What is the difference between pretraining and fine-tuning an LLM?
Pretraining teaches an LLM general language understanding using massive unlabeled text, helping it learn patterns, semantics, and reasoning from next-token prediction at scale.
Fine-tuning takes this pretrained model and adapts it to a specific task or domain using a much smaller, targeted dataset.
3.What are the major steps in data preparation for pretraining LLMs?
The major steps include Unicode normalization, ASCII filtering, repeated sequence removal, gibberish removal, and deduplication, followed by tokenization, sequence packing, and finally splitting the data into training and validation sets and storing it efficiently for LLM pretraining.
4.How does the NVIDIA NeMo Curator help with data deduplication?
It uses MinHash + LSH + GPU-accelerated connected components to efficiently identify and remove exact and near-duplicate documents at large scale.
5.Why is tokenization essential for LLM pretraining?
Tokenization converts raw text into numerical tokens that LLMs can process. It breaks text into consistent subword units, handles rare or complex words reliably, and ensures the model can learn language patterns effectively within its context window.