Production-ready AI agents demands engineered context, not just better prompts, reliability depends on structured information ecosystems.
The right information, in the right format, at the right time drives precision, scalability, and cost efficiency.
Context engineering transforms AI from smart demos into dependable, real-world systems that deliver consistent business value.
The four pillars of Context Engineering—dynamic information flow, tool integration, memory architecture, and format optimization—keep AI systems precise and production-ready.
Building AI agents that work in demos is easy, but creating ones that survive in a production environment is a completely different challenge. We at KeyValue, developed a platform to help Customer Success teams act fast by connecting their meeting transcripts, emails, and account data with AI-driven insights. Our journey building a reliable AI assistant revealed that successful, scalable systems are built upon four fundamental pillars of Context Engineering. If any one of these pillars is weak, the agent becomes unreliable.
Our early prototype could perfectly answer questions about sample customer accounts, summarize meeting transcripts, and generate professional-looking reports. But we still foresee the problems it might cause in real-world scenarios when using real-time data. Queries might return irrelevant results, responses would go wrong, and processing costs will skyrocket.
We realized that a reliable production system isn’t just about better prompts or smarter models. It’s about engineering the entire context ecosystem that surrounds AI. In the Customer Relation Management platform we developed, Context Engineering has become the foundation of everything we build. It’s about giving AI the right information, in the right format, at the right time, while maintaining quality, relevance, and cost efficiency.
The four pillars of context engineering
Pillar 1: Dynamic information flow
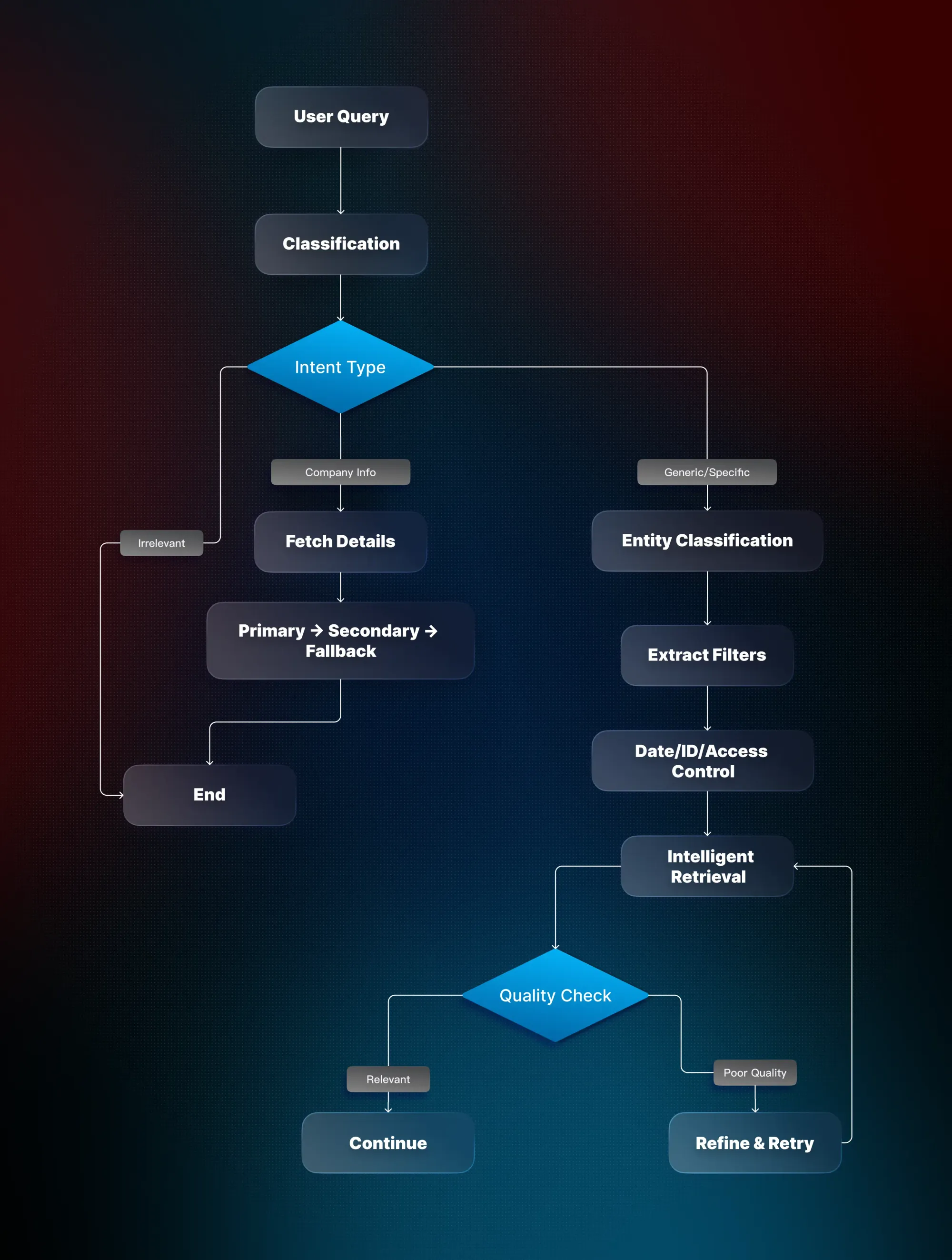
The first pillar is all about providing the AI with the right information at the right time. For our assistant, this means connecting vast, interconnected data: customer accounts, meeting transcripts, emails, and action items. More context isn’t always better; quality and relevance matter most.
Our assistant uses intelligent retrieval strategies. When a user asks, “Show my upcoming meetings this week,” the system identifies the intent, extracts structured filters like meeting dates or company, and retrieves only the most relevant data. This prevents what we call the “Retrieval Death Spiral,” where irrelevant context snowballs into increasingly inaccurate responses.
At the same time, background processes continuously consolidate insights. Company summaries, sentiment trends, and topic clustering run in the background so that every query is answered with the latest intelligence. For example, when a user asks, “How is the Acme Corp account doing?” The system instantly leverages recent interactions, meeting highlights, and sentiment scores to provide a complete and timely answer.
Pillar 2: Tool integration and orchestration
An AI agent that cannot perform actions is merely a static knowledge base. Ours doesn’t just answer questions, it interacts with tools, generates structured cards, triggers summaries, and produces professional templates like QBR agendas or renewal emails.
To handle this complexity, we built a graph-based pipeline that orchestrates every step. Each query is analyzed to determine the best path: fetch data, summarize, or generate a template. Each tool call is access-controlled, ensuring users only see data they’re authorized to access.
We also implemented a resilient runner architecture. If one model or tool fails, the system switches to backups or provides polite fallback messages. This ensures that users never see cryptic technical errors. For instance, if a calendar integration is temporarily unavailable, the assistant suggests approximate time slots instead of failing silently.
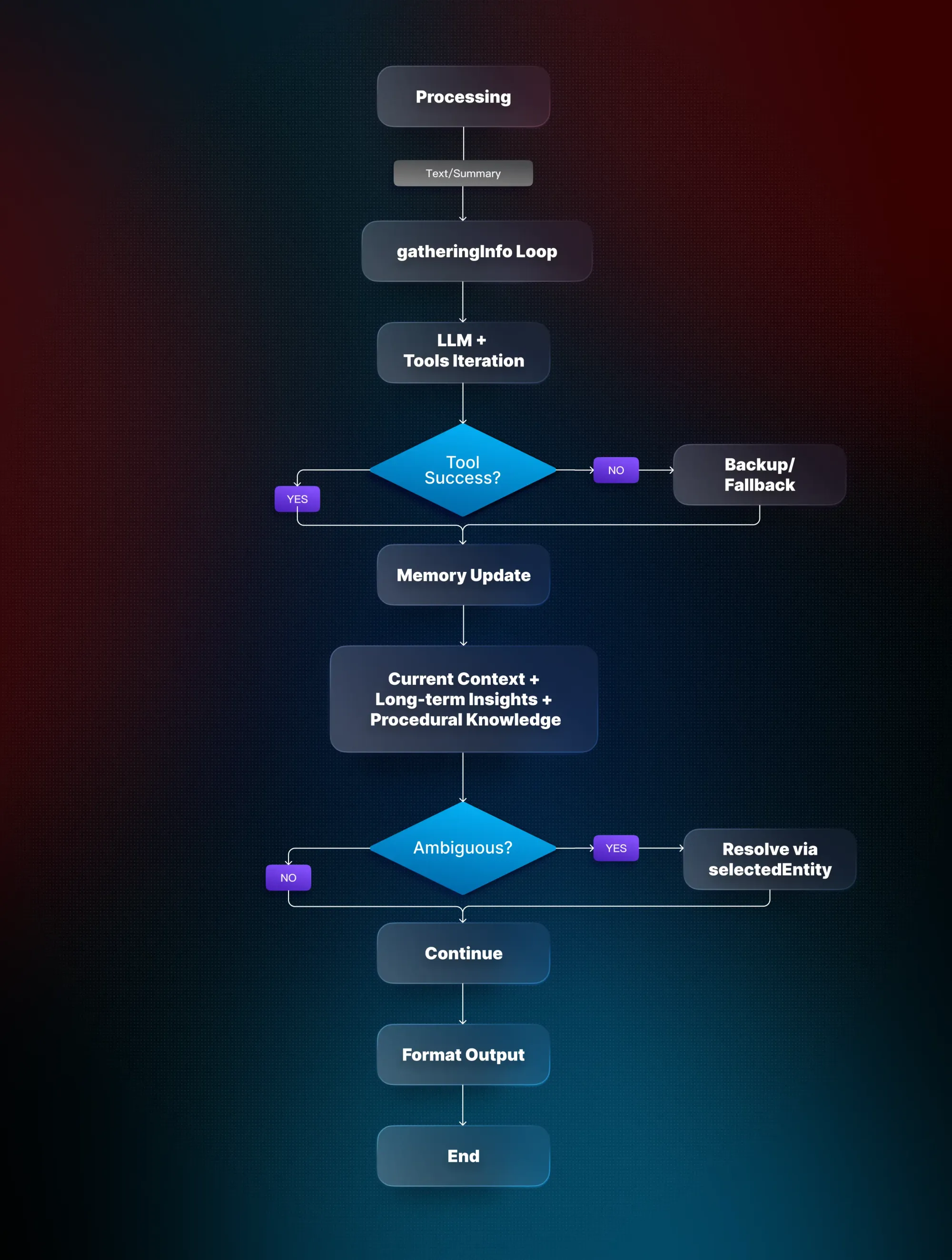
Pillar 3: Memory architecture
Effective AI product development requires multiple types of memory working in harmony. Our assistant remembers current conversation context, consolidates long-term customer insights, and maintains procedural knowledge for tool use.
We use a hierarchical memory pattern, where immediate context takes precedence but long-term patterns and insights are efficiently consolidated. Ambiguities like “this account” are clarified instead of guessed, preventing incorrect assumptions from cascading.
Memory consolidation runs in the background. Weekly interactions, emails, and meetings are distilled into concise company summaries, sentiment trajectories, and relationship maps. This ensures that the assistant answers questions with both precision and efficiency, without wasting resources or overwhelming users.
Pillar 4: Format optimization
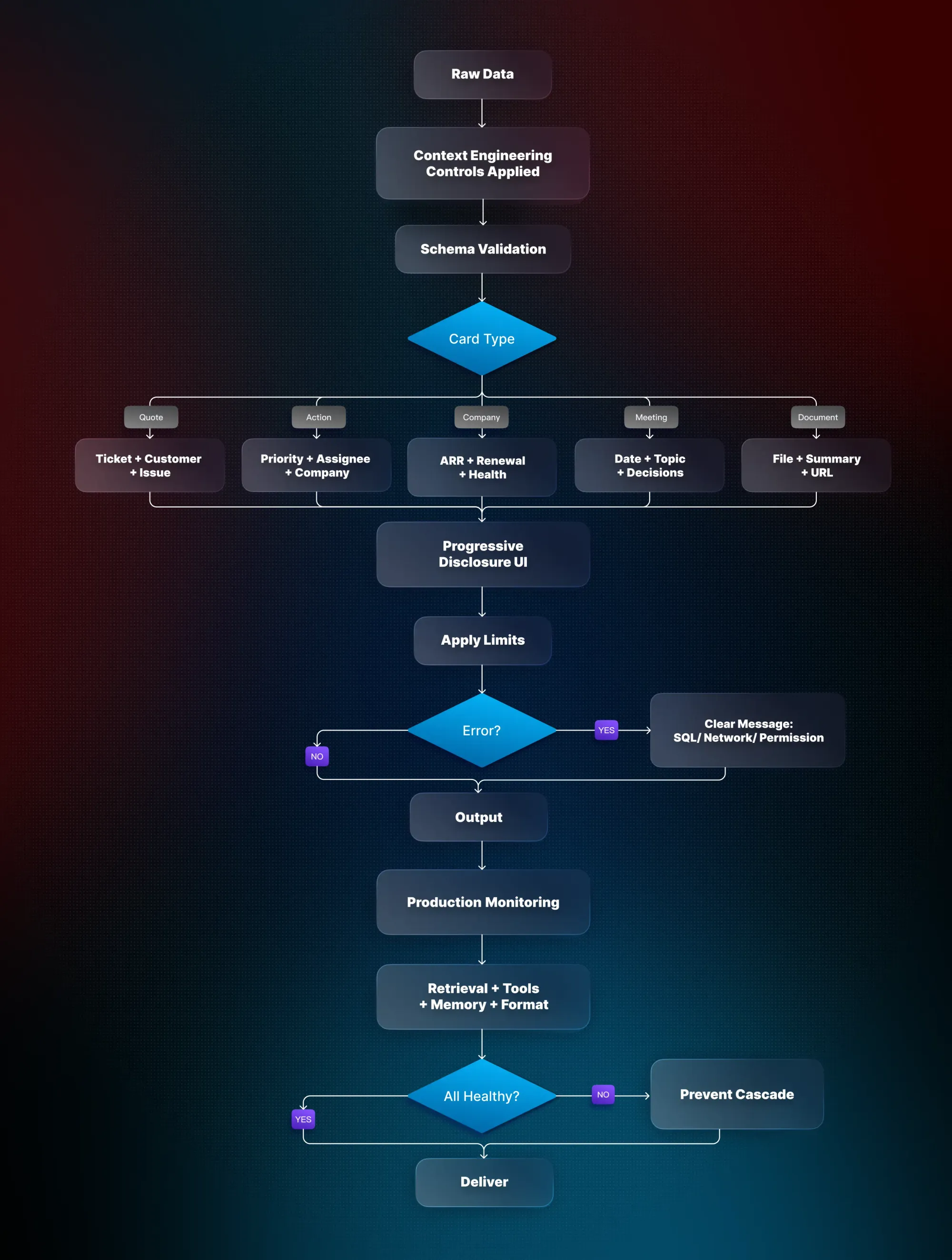
How information is structured is as important as what is provided. Poor formatting can render even perfect data useless. At KeyValue, our team standardises context into structured schemas while developing the platform, making it easy for the AI to interpret and act.
For example, instead of a verbose customer support ticket, the AI sees a clean block:
{"ticket": "2024-001", "customer": "John Smith <john@example.com>", "issue": "Cannot access account"}
We also use a card-first approach for the user experience. Company cards summarize ARR, renewal timelines, and health scores. Meeting cards highlight key decisions and action items. Quote cards capture customer statements with context. This progressive disclosure ensures that Customer Success teams get clear, actionable information without being overwhelmed.
Errors are also handled elegantly. Instead of confusing technical logs, the assistant delivers clear, actionable messages when tools fail, maintaining trust and reliability.
Integrating the pillars
The true challenge is getting all four pillars to work together seamlessly. Early on, we saw perfectly functioning components produce entirely wrong answers due to subtle interactions. For example, outdated retrieval results stored in memory could propagate through tool actions and formatted outputs, creating confidently wrong responses.
To prevent this, we implemented production monitoring and health checks. Each pillar is independently tracked, and integration points are monitored for failures. Retrieval accuracy, tool reliability, memory coherence, and format consistency are all measured to maintain system reliability at scale.
Why context engineering matters in AI product development
Context Engineering isn’t about giving AI more information. It's about building reliable, production-grade systems. This insight allowed us to move beyond prompt engineering to a robust architecture that handles messy real-world data, unpredictable users, cost constraints, and security requirements.
By focusing on context, Customer Success teams now gain instant insights, professional summaries in seconds, and never miss critical account updates. What stands out in the product isn’t the AI model but it’s the engineered context that makes it reliable.
Context Engineering represents a new discipline at the intersection of AI and systems engineering. It’s about making AI practical, reliable, and actionable in real business environments, and at KeyValue, it has fundamentally transformed how our teams deliver value.
To dive deeper into how context engineering turns AI agents from clever demos into dependable, production-ready systems, read our blog.
FAQs
Why do AI systems fail, and how does context engineering help?
Most AI failures are not due to the model itself but to missing, outdated, or poorly structured context. Context engineering ensures the AI has the right information, tools, and memory at the right time, preventing errors, forgetfulness, and unreliable outputs in complex tasks.
What is the difference between prompt and context engineering?
Prompt engineering tells the AI what to do. Context engineering provides the AI with what it needs to know, including the right data, tools, and memory, so it can perform tasks accurately and reliably.
What is a context engineer?
A context engineer designs and manages the AI’s information ecosystem, ensuring models have access to the right data, tools, and memory at the right time to execute complex, multi-step tasks reliably.
What are the skills of context engineering?
Key skills include designing dynamic information flows from multiple sources, integrating and orchestrating tools, managing memory (short-term, episodic, long-term), optimizing context structure and relevance, and handling failures while balancing cost and performance.
What are the four pillars of context engineering?
The four pillars are dynamic information flow for timely data, tool integration and orchestration for reliable execution, memory architecture to manage short- and long-term context, and context optimization to structure and prioritize information effectively.